On 7.0.29, try extending the wakeup interval of all battery powered devices from 1800 to something like 86400 or 43200 (i.e. 24 or 12h). This will be a huge relief to your network. As of now the entire wakeup process (wakeup, poll, nnu) takes over 1minute and during that time, your network is disabled. Looking at the logs you will have data collision on the network and if you have say 10 battery operated sensors on your network and they wakeup every 30min, you will end up disabling your network for 1/3 of its time. When network collision occur, the data is lost and when one device wakes up while another is doing its nnu… well then the vera doesn’t know it woke up. If this happens twice to this device, then the vera says it cannot detect the device and this is the song and dance of the “can’t detect device” which has been plaguing the vera. When this causes commands to lag too much, we end up with tardy commands (command lag) which, when they become too long cause the vera to crash itself and reboot. Imagine combining this absurd wakeup process with a nightly network heal and you get the perfect storm!
Note that the wakeup interval is a configuration of the node and not of the vera. The variable “WakeupInterval” is used by the vera to calculate how long before the vera will go without a wakeup signal from the device before it will flag it as “cannot detect”. The vera will let go of one interval but will flag the device after the second time it misses the wakeup. (2x the value of that variable). The
“ConfiguredWakeupInterval” variable keeps a record of the value the vera used the last time it sent it to the device. Changing the wakeup interval can be done through the device settings page and will require waking up the device manually for the vera to send that configuration change to the device.
The poll settings on the other hand are a parameter of the vera only and do not require a device reconfiguration (the firmware will do it if you try changing this variable from the device settings page but is really not needed). I prefer doing it with lua code and then run a luup reload. The code below will disable polling on all non battery operated devices:
for k, v in pairs(luup.devices) do
local var= luup.variable_get("urn:micasaverde-com:serviceId:ZWaveDevice1", "PollSettings",k)
local bat = luup.variable_get("urn:micasaverde-com:serviceId:HaDevice1", "BatteryLevel",k)
if var ~= nil and v.device_num_parent== 1 and bat == nil then
if var ~= 0 then
luup.variable_set("urn:micasaverde-com:serviceId:ZWaveDevice1", "PollSettings", "0", k)
luup.variable_set("urn:micasaverde-com:serviceId:ZWaveDevice1", "PollNoReply", "0", k)
end
end
end
You can then determine afterwards if you need to enable polling on some specific devices. You could do it manually for your FLiRs too by changing the “PollSettings” variable to 0. Other battery operated devices will still get polled when they wakeup and I am still requesting to eliminate this function which takes 3s of zwave bandwidth in not very useful way which could be 0.
On the upcoming 7.0.30, a few things I have requested have been implemented:
- Disable nightly heal. I will say and repeat this again. The heal is not a maintenance procedure. It is heart surgery. Doing this nightly will get you to certain death. It should be used only manually by the user when he knows there is a problem. Not used properly, it leads to self-destruction and the only person who can know when to use it is the user. It should never be automated. Thank you ezlo for finally listening and allowing us to disable it.
Lua code to disable nightly heal:
luup.attr_set("EnableNightlyHeal",0,0)
- Disable the Wakeup nnu: This is another aberration forcing a mini self heal of a perfectly working device. Why? Because if the device wokeup and the vera can detect it and is able to send it this command then why for goodness sake would you want to ask it to update neighbor nodes? The only case when this would be needed is when the network is broken and the node is not reachable which is self defeating. This function should never exist and defies logic. Again thank you @edward for finally allowing us to disable this. It cuts down the wakeup time of the battery operated node from 1 min each time down to ~2-3s. Saves a ton of battery life, improves stability of the network of the vera by freeing precious useable bandwidth (decreasing the overhead). It also reduces/eliminates the recurrent “can’t detect device” messages caused by devices waking up while the network was busy doing useless things. The wakeup polling remains another extra useless overhead for most devices which has not been disabled but is much less of an issue than the wakeup nnu.
This is the luup call to disable the wakeup nnu for all devices which wakeup (i.e battery operated devices)
for k, v in pairs(luup.devices) do
local var= luup.variable_get("urn:micasaverde-com:serviceId:ZWaveDevice1", "WakeupInterval",k)
if var ~= nil and var ~= 0 and v.device_num_parent== 1 then
luup.variable_set("urn:micasaverde-com:serviceId:ZWaveDevice1", "DisableWakeupARR_NNU", "1", k)
end
end
- TimeJump auto luup reload. The luup engine also has a function to kill itself and reload whenever it detects a time jump. This can be caused by a time zone change, a DST or end of the month or… somehow when the zwave chip has too much lag for the engine. The problem I have with this is that the reload does absolutely nothing but wipe out your data in the dram (notably ongoing scene timers), risking data corruption. It does nothing about the cause or consequences of the timejump. We will now have the ability to disable it!
lua code to disable the time jump reload:
luup.attr_set("ReloadOnTimeJumps",0,0)
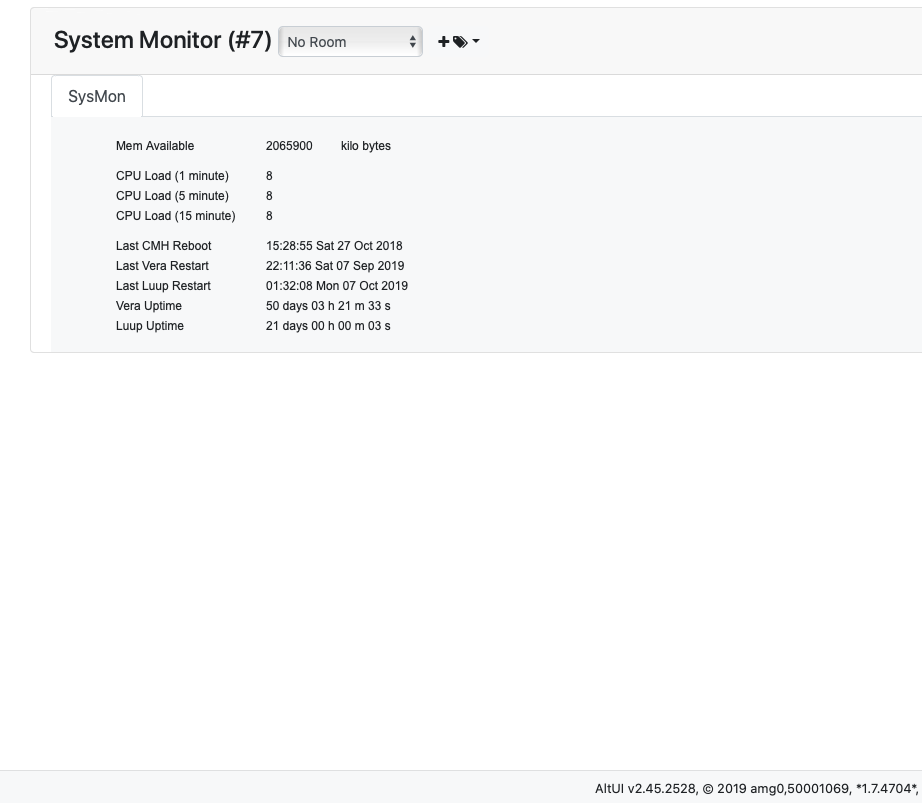
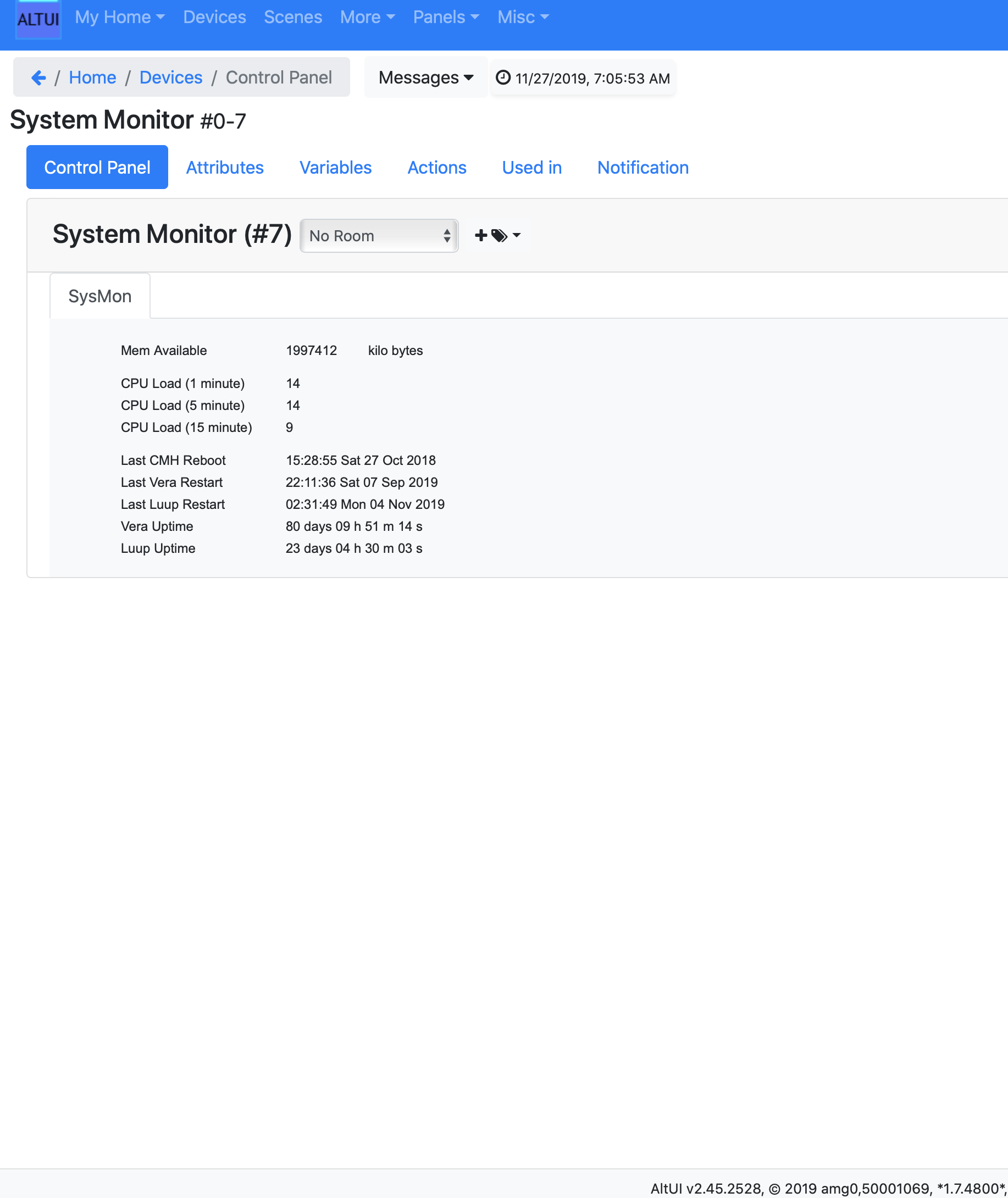
Note that at the moment, as reported by @therealdb this last feature of 7.0.30 is buggy. It prevents time based scenes from triggering and also causes a small memory leak as you can see below:
At this moment, the released version of 7.30 has been pulled mostly due to update failures and a poorly tested/validated kernel which is causing Christmas light mode and disables extroot. For those who have an old SATA ssd laying around, I proposed getting a USB to SATA dongle and head to the extroot thread to first extroot your vera and then to run a hybrid upgrade whereby only the program side of the vera upgraded and not the OS/kernel which enables all the new features without suffering from the odd problems of the new kernel.